
{kind=link}
Overview
In general, a pipeline is a linear sequence of specialized modules used to design or execute a computer instruction in successive steps. Similarly, data pipeline is a generic term for moving data from one place to another. For example, it could be moving data from one server to another server.
Of the many data pipeline methodologies present, this article discusses in brief about the most used ETL pipeline.
Outline of this article:
- Introduction to ETL pipeline
- Example
- Stages in ETL pipeline
A small example code for ETL pipeline can be found in my GitHub.
Introduction to ETL Pipeline
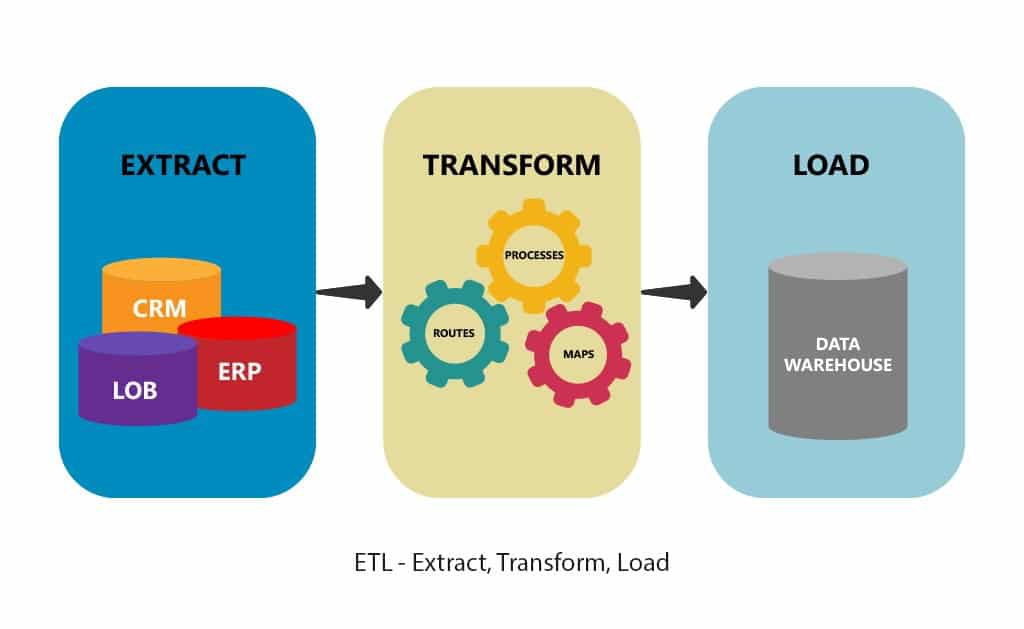
ETL is a specific kind of data pipeline and found very common in usage. ETL stands for Extract, Transform, Load. As the name suggests, an ETL pipeline consists of three distinct but reciprocally connected steps. It is used to orchestrate data from multiple data sources not once but may times to build data storage systems like data warehouses, data hubs or data lakes that exist to support the analytics of an enterprise or data sharing.
Example
Imagine that there is a database that contains web log data. Each entry in the data contains IP address of a user, timestamp, and the link clicked by user.
Think of a scenario where you want to run an analysis of links clicked by city and by day. You would need another data set that maps IP address to a city, and you would also need to extract the day from the timestamp.
With an ETL pipeline, you could run code once per day that would extract the previous day’s log data, map IP address to city, aggregate link clicks by city, and then load these results into a new database. That way, a data analyst or scientist would have access to a table of log data by city and day. That is more convenient than always having to run the same complex data transformations on the raw web log data.
Using ETL pipeline makes sense because, before the usage of cloud computing, companies and businesses used to store their data on private servers that were expensive and running queries on huge datasets could be very expensive in terms of time and economy.
Stages in ETL
Before loading data into a data storage system, it is essential to prepare it in order. The combination of steps in ETL pipeline provides some functions to assure that the business requirements of the application are achieved.
Basic ETL pipeline can be categorized into following stages:
- Extracting data from various sources
- Transforming data and readying it for future operations
- Loading data into required storage system
Now, let’s look at each step in brief.
Data Extraction
The objective of the extraction process in ETL is to retrieve all the required data from the source with ease. The most common data sources from which data can be extracted are:
- Databases
- Files
- Web
- Other sources like user feeds (RSS feeds)
Understanding how the data is produced from source and the format it can be stored is very important. The common file formats seen in data science are:
- CSV: CSV stands for comma-separated values. These types of files separate values with a comma, and each entry is on a separate line. Oftentimes, the first entry will contain variable names.
- JSON: JSON is a file format with key/value pairs. It looks like a Python dictionary. Each line in the data is inside of a squiggly bracket {}. The variable names are the keys, and the variable values are the values.
- XML: XML is very similar to HTML in terms of formatting. The main difference between the two is that HTML has pre-defined tags that are standardized. In XML, tags can be tailored to the data set. Here is what this same data would look like as XML.
- DB files (SQL databases): SQL databases store data in tables using primary and foreign keys.
- Text files: A text file (.txt) will contain only text.
Data Transformation
After the data is extracted, it needs to be made ready for next task that might be data analysis or as an input to a machine learning.
For instance, data engineers and data scientists often work with data coming from more than one source. They might need to pull some data from a CSV file, other data from a SQL database, and then combine those two datasets together. Hence, the original datasets are transformed to create new datasets.
Transformation of data includes:
- Cleaning and combining data from multiple sources
- Working with encodings
- Handling dummy variables, duplicate rows, and outliers in data
- Normalizing the data wherever required
- Engineering new features
Data Loading
The last step in ETL pipeline is “load”. Now that the data is transformed, it must be stored somewhere otherwise, the progress will be lost. There are many options for storing the transformed data. What option to choose depends upon the business needs.
For example,
- Structured data can be stored in a SQL database
- If the data fits in a pandas data frame, it can be stored in a CSV file
Some of the ways to store the transformed data other than SQL, CSV, or JSON can be found in the link here.
Other Data Pipelines
ELT (Extract, Load, Transform) pipelines have gained attention since the surfacing of cloud computing. Cloud computing has lowered the cost of storing data and running queries on large, raw data sets. Many of these cloud services, like Amazon Redshift, Google BigQuery, or IBM Db2 can be queried using SQL or a SQL-like language. With these tools, the data gets extracted, then loaded directly, and finally transformed at the end of the pipeline.
Summary
In this article, we have seen brief introduction to ETL (Extract, Transform, Load) pipeline, and overview of each step. A small example of ETL pipeline can be found in my GitHub. Have a look at it to understand the working of ETL pipeline.
Hope you gained some knowledge reading this article. Please remember that this article is just an overview and my understanding of ETL pipeline that I read from various online sources.